This is one of my favorite bugs lately because it lied so well. I sent a long Thai message into my AI, got silence back, and at first it looked like the usual suspects: maybe the model got confused, maybe the session was too heavy, maybe the agent was stuck. The real culprit turned out to be much smaller and much nastier: a 1KB PTY input buffer that silently dropped the tail of the message.
I wanted to document this one because it's a clean example of what changes when AI stops being just a chat window and starts becoming a real working agent. Once your AI is attached to terminals and real infrastructure, the failures often have nothing to do with prompts. They happen down in the plumbing: bytes, buffers, timing, encoding.
The weird symptom: long Thai broke, long English didn't
The bug showed up when I sent a normal work message in Thai through Newton's chat UI to Codex. Just a few hundred Thai characters explaining a task. The AI didn't answer. The rollout didn't grow. It looked like the message never really made it through.
The interesting part was the pattern. If I sent a similarly long message in English, it worked fine. If I sent a shorter Thai message, it also worked fine. So this wasn't "Thai is unsupported" and it wasn't "the model is bad at Thai." It was clearly some interaction between message length and delivery.
That immediately pushed me away from model-level guesses and toward transport-level debugging. I've seen this movie before. A while ago my AI had to learn to wait for the real terminal cursor before typing, because the message path was racing ahead of the agent's actual readiness. This felt like the same family of problem: not intelligence, just delivery.
Ruling out the obvious wrong explanations
One thing I care about a lot when debugging is not rewarding the first guess. Systems like this are good at producing plausible lies. So before changing anything, I wanted evidence.
- Not a huge session. I reproduced it on a fresh, tiny session with almost no history and the bug was still there.
- Not the model thinking slowly. The rollout on the AI side didn't grow at all, which meant the prompt wasn't even entering the thinking phase.
- Not a cold-start timing issue. This was different from the cursor-readiness bug. The terminal prompt was already visible. The machine was ready. The text still got mangled.
- Not Thai in general. Short Thai inputs passed fine. Only longer ones failed.
Once those were out, the shape of the problem was clear: the terminal path depended on bytes, not characters.
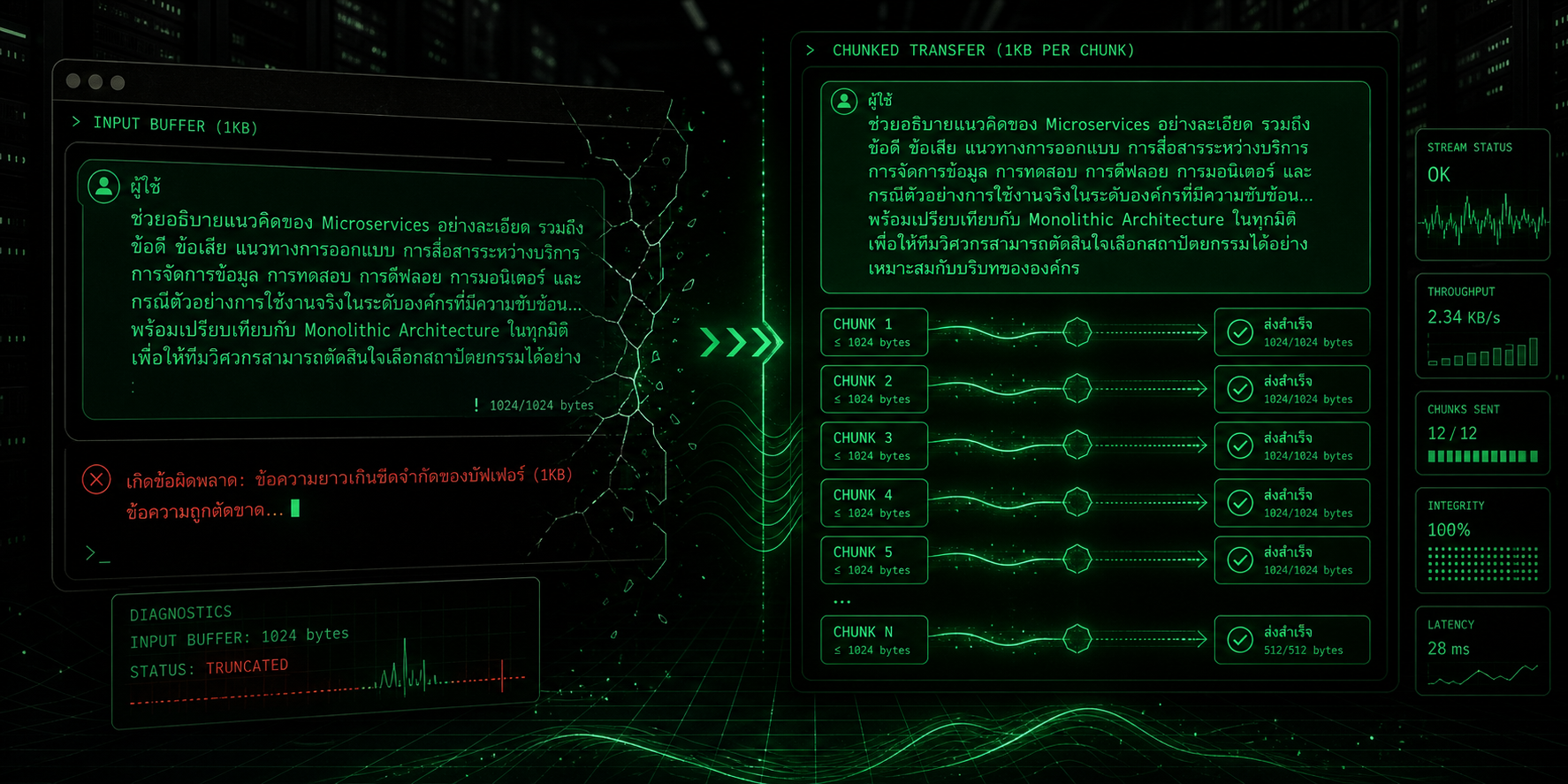
The real cause: one write, one 1KB ceiling
On the Codex side, Newton talks to the AI through a PTY, a pseudo-terminal. In plain English: the system spins up a terminal-like process and types into it as if a human were typing into a shell window.
The original implementation was simple. When the user sent one message, Tim would take that whole message and write it into the PTY in one shot. That's a very human assumption: one message, one write.
But direct PTY testing showed the receiving side only handled about 1024 bytes per single write. Go over that, and it didn't raise an error. It didn't warn. It didn't say "partial write." It just silently dropped the overflow. That's why this bug felt haunted.
And that's also why Thai hit it sooner than English. In UTF-8, ordinary English letters are usually 1 byte each. Thai characters are typically around 3 bytes each. So the same sentence length to a human eye can be wildly different at the byte level.
- 455 English characters is roughly 455 bytes. No problem.
- 455 Thai characters is roughly 1,165 bytes. That smashes straight through the 1KB ceiling.
So the model wasn't failing to understand the prompt. The model wasn't even getting the full prompt. The tail had already been thrown away before it reached the AI.
The plain-language analogy
If you want the non-technical version, imagine passing handwritten instructions through a mail slot that only fits one thin sheet at a time. English is small handwriting. Thai is big handwriting. If I try to shove a long Thai note through the slot all at once, the last section bends, stays outside, and falls to the floor.
The person on the other side isn't dumb. They aren't misreading the note. They simply never received the last part of it.
The fix: stop shoving, start chunking
Once the root cause was clear, the fix was straightforward. If the terminal can only safely absorb a limited amount per write, don't exceed that limit in the first place.
So Tim changed the typing logic from "write the entire message at once" to "type in small chunks." Concretely, it now splits the message into chunks of about 40 characters and feeds them into the PTY one piece at a time with a tiny pause between chunks.
For Thai, 40 characters is roughly 120 bytes. Safely below the ceiling. Even with punctuation mixed in, it stays in the comfort zone. The destination gets the whole message, just in a steady stream instead of a single oversized dump.
I like this fix because it isn't some weird hack. It's just respecting the truth of the system. The receiving pipe can handle only so much at once, so send data in a shape the pipe can actually swallow.
Why this kind of bug is easy to misdiagnose
This is exactly the kind of bug that makes people say "AI is flaky" when the model isn't the problem at all. From the outside, all you see is: I typed something, the AI didn't respond, maybe it's confused. But the real problem lives a layer lower.
It reminds me of another production issue I wrote about in the hotfix Tim pushed to six customer servers. The customer-facing symptom looked simple. The underlying issue was not. That's normal once an AI agent is doing real engineering work on real systems.
I've also learned this while making Tim feel consistent across multiple engines. In the "one Tim across three engines" fix, the user-facing issue was "this assistant suddenly feels like a stranger." The real fix had nothing to do with tone. It was memory injection at session start. Same pattern again: what the human sees and what the system is actually doing are often very far apart.
The result after the fix
After switching to chunked typing, the exact same long Thai message that used to fail went through cleanly. I verified it both on direct PTY tests and on the real Newton flow. Rollout grew normally. The AI received the full task. No more silent truncation.
Just as important, the fix didn't create collateral damage. English still feels fast. Short messages don't become annoyingly slow. And the change plays fine with the other protections already in the pipeline, like readiness detection and cross-session memory handling.
That's the bigger lesson for me: once you build AI agents that touch real terminals, plumbing quality matters as much as model quality. A brilliant model behind a broken pipe still looks broken.
What this says about how I think about AI systems
A lot of AI discussion stays at the model layer: which one is smarter, which prompt style works best, which tool call format is cleaner. All of that matters. But in production, many of the most painful failures come from the machinery around the model: buffers, process state, encoding, terminal behavior, network timing.
That doesn't make AI less interesting. It makes it more real. That's why I don't want an AI that just gives me text. I want one that can trace the whole path, find the broken layer, patch it, and test the result.
If this kind of story is interesting to you, the closest sibling post is probably the one about the blinking cursor bug. Different failure, same principle: the thing that breaks the experience is often one thin layer between the human and the model.
This is exactly the kind of work I built Newton for. Not an AI chat box that only answers, but a private AI agent on your own server that can inspect files, read terminal state, debug weird infrastructure bugs, and keep improving the real system underneath your business. If you want an AI that can go all the way down to the byte-and-buffer level when that's what the problem demands, Newton is the thing I use myself every day.
— Pond